First and foremost, let's start with the definitions.
A zip bomb is a usually malicious compressed file that is usually designed to render useless
an antivirus engine to create an opening for another computer virus.
Normally, a zip bomb negates an antivirus engine by tricking it into scanning the entire archive,
which takes up an unimaginably large amount of time, disk space, and memory. However,
modern antivirus engines are able to recongnize when a file is a zip bomb, and will avoid scanning through it.
Despite this, what I'm looking at isn't its ability to destroy antivirus engines or create opening for other
viruses to attack - instead, let's take a look into the marvelous compression ability of zip bombs, and the science behind it.
When talking about zip bombs, I will split them into two catagories:
Traditional zip bombs.
The "better" zip bombs.
You have have heard of another type of "zip bomb": the zip quine.
However, I would like for you to note that this is an entirely different thing compared to a zip bomb.
While it can be used in theory to disable antivirus engines &c like how zip bombs do,
they are much more sophisticated compared to zip bombs and deserves its own article that I will write sometime in the future.
That leaves us with the two types of zip bombs, the traditional and the better ones. So without further ado, let's take a look at them.
Traditional zip bombs
A traditional zip bomb is one that uses recursive zipping to acheive high levels of compression.
A zip bomb that use the .zip format
must cope with the fact that the compression algorithm .zips most commonly use, DEFLATE,
cannot achieve a compression ratio greater than 1032. Why? Well let's take a look.
Compression
Example 1 - intuition
First, let's understand what compression actually is. Take a look at the image below:
How would you describe this image?
Well, we can say that: the top-left box is blue, the top-middle box is blue, the top-right box is blue,
the middle-left box is blue, the middle-middle box is blue, the middle-right box is blue,
the bottom-left box is blue, the bottom-middle box is blue, and the bottom right box is blue.
Whew, that was certainly a mouthful wasn't it? If you were trying to describe to someone this image in the most efficient and effective way,
the method I used would certainly not be a viable one. So instead, let's try something else.
How about this? We can say that: there are 9 boxes, arranged in a 3x3 pattern, where all the boxes are blue.
That was certainly a much more efficient way of describing the image, without the redundancies of having to denote each box as blue individually.
What we have done here, is what data compression does. It takes a file and subtracts the redundancies that may be contained in the file, effectively
compressing it, lowering the file size.
Now notice something - we can shorten the description even further! Looking back at our "compressed" description, we see that we can take away
"there are 9 boxes" and still have our description be feasibly understood, and reconstructed perfectly.
This is an example of how different compression algorithms work, and how some are able to compress more than others in different cases.
They each have their own methods of reducing and eliminating redundant data within a file, while still maintaining the ability to perfectly
reconstruct the original file itself - lossless compression.
Then there are lossy compression algorithms. Referring back to our aforementioned example, let's just say instead that all boxes are blue.
We can see how this still describes our image, but when trying to reconstruct it, we don't know how many boxes there are. We can estimate that there may be
around 4-16 of them, but we can't be sure, since there is no information regarding it after compression.
Let's take a dive into a more rigorous example of compression.
Example 2 - rigorous
In a typical file, the data is divided into bytes. Unless there is a special exception, a byte is 8 bits long, where a single bit is a 0 or a 1.
In UTF-8 encoding, each byte represents a single character. For example, the character, and in this case, byte, "0" is encoded by the bits "00110000".
Note that in other non-latin based languages, such as Mandarin or Arabic, a character may be multiple bytes.
However, not every byte of data encodes as much information as others in a sense. For example, think of all the English words you can that start with "Q" or "T".
How many of them don't have a "U" or "H" immediately superceeding the "Q" or "T"? Likely none of them! Knowing this, how much "information" do you think the "U" and "H"
actually contain, in a sense? What if you omit the "U" and "H"s, or replace the two letter pairs with a just a single character?
Again, we can see the points I have shown in Example 1 surface: remove the redundant information - this is the essence of data compression.
Now let's think of vowels in the English language. Vowels are part of a very small set of the alphabet, and thus will convey less information than consonants.
In fact, you could get rid of vowels completely and still understand what a sentence means. For example, let's try to take away the vowels from the following sentence:
This is a sentence without vowels and will still be readable.
We get:
Ths s sntnc wtht vwls nd wll stll b rdbl.
Try that with consonants, and all meaning is lost:
This is a sentence without consonants and will not be readable.
i i a eee iou ooa a i o e eaae.
Now there, this does not mean that vowels are not important, and that they can be ignored. This just means they carry less information than
consonants, and when compressing, can be valued less than consonants. This is what data compression tries to achieve: it looks at data,
gets an idea of how much information each character conveys, and then tries to minimize that. And as a result, a single character may no longer be 8 bits long -
a very common character may be represented by only a few bits.
Revisiting the "QU" and "TH" observation I have noted above, we have that groups of characters may be common enough that we can represent them by a smaller number of bytes.
For example, with the "QU" example above, if you're using "QU" words often enough, we could replace them with fewer than 16 bits. And words with "TH" in them?
We could also replace every instance of "TH" with something less than 16 bits. What about the word "THE"?
That's a very common word that takes up 24 bits uncompressed, but could take up fewer bits.
I believe this is good enough of an analogy. If you, dear reader, still don't understand parts of these two examples, please give it a slow and detailed re-read.
With that, we can move on: let's look at zip files.
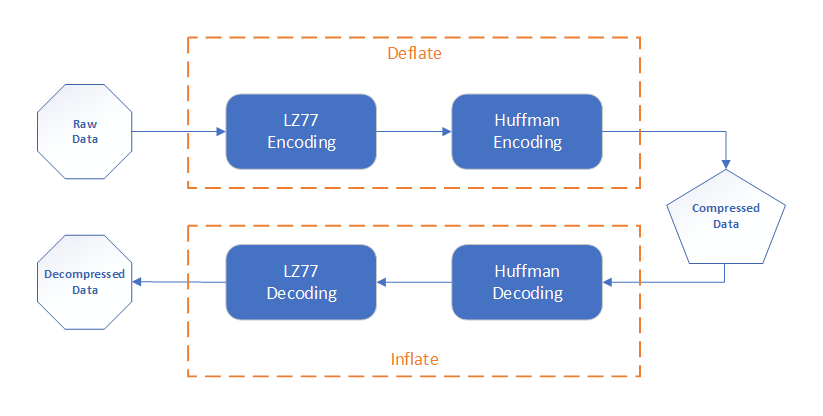
Zip and DEFLATE
While zip files may use a variety of compression algorithms, the compression algorithm
DEFLATE is the most common.
As a result, almost all zip bombs utilize this algorithm, and thus, we'll take a look at this algorithm in particular.
The algorithm DEFLATE is actually a combination of two algorithms, LZ77 and Huffman Coding.
LZ77
LZ77 is a dictionary based compression algorithm.
A dictionary based algorithm is one that replaces an occurrence of a particular sequence of bytes in data with a reference to a previous occurrence of that sequence.
What LZ77 does is that it looks for groupings of bytes, and when it finds a repeat of a grouping, it will encode the superceeding groups in a length-distance pair.
A length-distance pair denotes the amount of characters that are repeated - L, the distance where the preceeding repeating group can be found - D, and
the character immediately superceeding the longest matching group - C.
Firt off, I would like to remark the fact that the "C" aspect of a length-distance pair is usually a temporary element, and will be excluded from the final result.
The reason of adding the third element C in the length-distance pair is for handling the case where no match is found in the search buffer.
In that case, the values of both D and L are 0, and C is the first character in current look-ahead buffer.
Now there, note that searches for length-distance pairs do not occur across the entire file, but instead only is made in a fixed number of bytes at one time.
This is to keep the distance number from getting really big and impairing the data compression efforts. For example, suppose you're trying to compress a multi-gigabyte
word document explaining the proof for Fermat's Last Theorem where you use the word "cringe" once at the beginning and once at the end, it won't make sense to have a distance
value that represents a position several gigabytes in size, since at some point, the number of bits needed to store the length-distance pair will surpass the bytes
you're compressing. This fixed number of bytes is the sliding window.
The sliding window is the length of bytes the LZ77 algorithm will look in to data group repeats, and maintains the historical data for future reference.
The sliding window contains two parts, a search buffer, and a look-ahead buffer. The search buffer contains the dictionary - the recent encoded data,
and the look-ahead buffer contains the next portion of input data sequence to be encoded.
In ZIP files, the sliding window is usually either 32KB or 64KB.
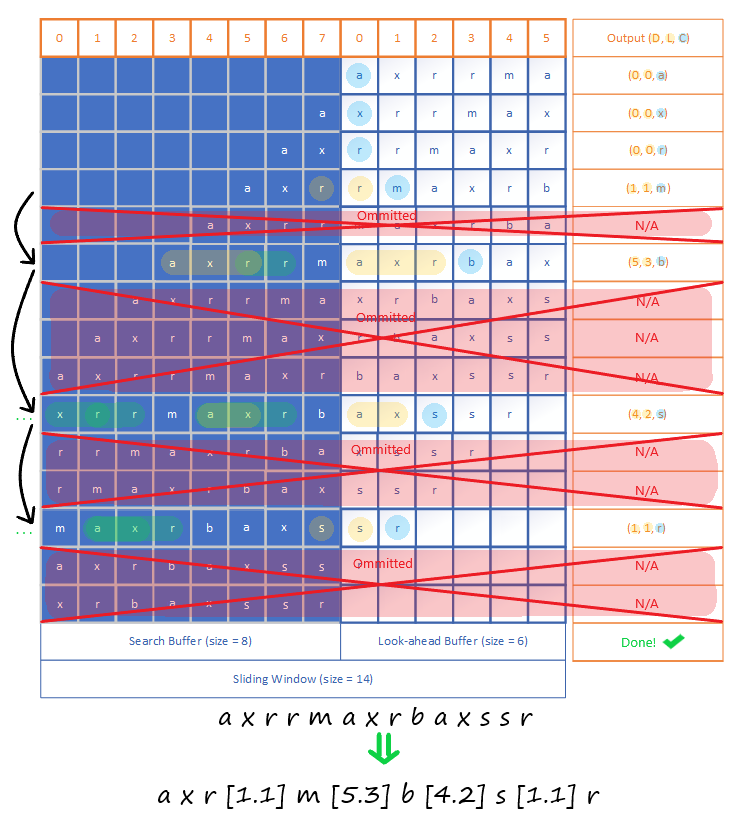
As an example, I have created a visual on the LZ77 algorithm that will "compress" the string "axrrmaxrbaxssr" below. If you don't understand any part of it,
please give it a careful re-analysis and refer to the color-coding of the different elements I've included.
Notive that due to the really inefficient way I've chosen to represent the length-distance pairs, and because this is a very small example,
we've actually made the example string longer. However, even with my inefficient representation, longer strings with more repetition would show noticeable size improvements.
An interesting side-note is that in a length-distance pair, the length can actually be greater that the distance value.
So you could have "length 5, distance 1" which would mean copying the last character five times.
Huffman Coding
Huffman encoding is a statistical compression method. It encodes data symbols, such as characters with variable-length codes,
and lengths of the codes are based on the frequencies of corresponding symbols.
Huffman encoding, as well as other variable-length coding methods, has two properties:
Codes for more frequently occurring data symbols are shorter than codes for less frequently occurring data symbols.
Each code can be uniquely decoded. This requires the codes to be prefix codes, meaning any code for one symbol is not a prefix of codes for other symbols.
For example, if code “0” is used for symbol “A”, then code “01” cannot be used for symbol “B” as code “0”
is a prefix of code “01”. The prefix property guarantees when decoding there is no ambiguity in determining where the symbol boundaries are.
Huffman encoding has two steps:
Build a Huffman tree from original data symbols. A Huffman tree is a binary tree structure.
Traverse the Huffman Tree and assign codes to data symbols.
Huffman codes can be fixed/static or dynamic, and both are used in DEFLATE.
Fixed Huffman codes can be created by examining a large number of data sets, and finding typical code lengths. When using fixed Huffman coding,
the same codes are used for all the input data symbols.
Dynamic Huffman codes are generated by breaking input data into blocks, and generating codes for each data block.
Here is an example of Huffman Encoding of the text "this is an example of a huffman tree":
Char
Freq
Code
space
7
111
a
4
010
e
4
000
f
3
1101
h
2
1010
i
2
1000
m
2
0111
n
2
0010
s
2
1011
t
2
0110
l
1
11001
o
1
00110
p
1
10011
r
1
11000
u
1
00111
x
1
10010
To the right is a chart showing the frequencies and bits that encode each character after using Huffman Coding. Encoding the sentence with this code requires 135 bits,
as opposed to 288 bits if 36 characters of 8 bits were used. Of course, this assumes that the code tree structure is known to the decoder and thus does not need to be
counted as part of the transmitted information.
All of this assumes that characters don't occur with the exact same frequency, which is generally true of human languages.
Random data however may have all bytes having identical frequencies, in which case the data becomes incompressible.
Thus, by intuition we can see that this is why you generally can't run a .zip file through DEFLATE and get a smaller file out of it.
In fact, doing so may sometimes result in a slightly larger file, as zips have a certain amount of overhead to describe the files it stores.
CRC-32 check
Although this isn't important for our purpose, I thought it would be worth mentioning that .zip files also contains a CRC-32 hash of each compressed file within it.
CRC-32 is a hash algorithm that generates a string called a hash after looking at a file and its contents. There are 232=4,294,967,296 different hashes CRC-32
can generate, so it's possible for two files to have the same hash. However, when decompressing data with errors having the original file and the error file having the same CRC-32
value is so incredibly unlikely, so it's doubtful if it's ever happened in the history of the world.
A DEFLATE encoded zip's compression limit
Now that we understand how zips and DEFLATE works, let's try to see how well it can compress data.
By intuition, and from the explanation above, we can reason that a compression algorithm will work the best if a file is extremely redundant;
for instance, a file filled with zeroes. So therefore, let's test how well DEFLATE can compress a file filled with a lot of zeroes.
We create a 50MB file filled with zeros and compress it using DEFLATE.
It should compress to be roughly around 49KB as demonstrated here.
So thus, empirically, DEFLATE is capable of compression factors exceeding 1000:1.
To find the theoretical limit, let's dive deeper into the DEFLATE algorithm and zip file structure itself.
The limit comes from the fact that one length-distance pair can represent at most 258 output bytes.
A length requires at least one bit and a distance requires at least one bit, so two bits in can give 258 bytes out,
or eight bits in give 1032 bytes out. A dynamic block has no length restriction, so you could get arbitrarily close to the limit of 1032:1.
We can also note that the current implementation limits its dynamic blocks to about 8KB
(corresponding to 8MB of input data); together with a few bits of overhead, this implies
an actual compression limit of about 1030:1. Not only that, but the compressed data stream is itself likely to be rather compressible
(in this special case only), so running it through DEFLATE again should produce further gains.
Due to this reason, traditional zip bombs rely on recursive decompression, nesting zip files within zip files to get an extra factor of ~1032 with each layer.
Referring back to the original purpose of these traditional zip bombs - to disable antiviruses, these nested zips will only work on antivirus engines
that scan recursively into each nest of zips, and now as of March 2021, most will not.
The best-known zip bomb, 42.zip, expands to a formidable 4.5PB
if all six of its layers are fully and recursively unzipped, but a negligable 0.6MB
if one were to only unzip the top layer.
The Traditional Zip Bomb
Ok, I lied. Although in theory, the ratio 1030:1 is the greatest the DEFLATE algorithm can achieve, we underestimated file redundancy and how that can
dramatically compress a file. Here we can see how compressing a 4GB
file of zeros becomes 138KB, giving us a ratio of 29089:1.
Why is this? Well, the length-distance pairs although limited at a maximum of 258 bytes, is extremely repetitive. In a 4GB
file of repeating data, there would be such a frequent occurance of the same length-distance pairs such that when DEFLATE applies the Huffman Algorithm,
the encoding of the length-distance pairs will be shortenned to the extent that they may be just 1 single bit. This will drastically increase compression ratio,
beyond even the theoretical limit. In our initial calculation, we assumed the Huffman Algorithm was capped in it's efficiecy by the restrictions of the length-distance pairs themselves,
but it would appear to be not so.
As we test compressing larger and larger files, as shown here, we see that our ratio remains at a similar point as the previous
test, this time reaching 29090:1.
(Uh if you're looking at the files inside the zips and asking why they are repeating characters I'll explain why below in the "Constructing a traditional zip bomb" section lol.)
It would seem that the maximum compression ratio evens out at around 29100:1. Let's attempt to calculate why this is. By dividing 29100 by 1032, we arrive at \( \frac{2425}{86}\approx 28.2 \). We can reason
that the efficiency of the Huffman Algorithm must account for 28 times more efficiency. Math time!
We can calculate the percentage of compression by using this formula: \[ 1-\frac{\text{Compressed size}}{\text{Uncompressed size}} \]
First let's assume a compression efficiency percentage of let's say, 80%. WLOG then let's say that we compressed a file of 10000 bytes. We can thus reason that
we have compressed the 10000 bytes into \( 10000-(10000\cdot 80\%)=2000 \) bytes. Thus our compression ratio would be 5:1, and by this, we can see that the percentage of
efficiency must be arbitrarily close to 100%.
(If you're wondering why I'm converting between percentage efficiency and compression ratio it's because the research papers on Huffman Coding efficiency
apparently are all in percentages lol. So annoyingggggg aaaaaaaaaa)
To go in reverse, we reverse our process. Since LZ77 has accounted for the 1032\( \cdot \)28:1 part of the ratio, we focus on the 28:1 ratio Huffman Coding brings us.
WLOG again assume a file with size of 10000 bytes has been compressed. Thus we have such that \[ \text{Uncompressed size}=10000 \]
\[ \implies\frac{10000}{\text{Compressed size}}=\frac{28}{1} \]
\[ \implies\text{Compressed size}=\frac{2500}{7}\approx 357\text{ bytes} \]
Therefore the percentage would be equal to approximately
\[ \implies1-\frac{\frac{2500}{7}}{10000}=\frac{27}{28}\approx\boxed{96.4\%} \]
This is not an unreasonable value, and as seen in Fenwick (1994).
Constructing a traditional zip bomb
Now let's move onto creating these marvelous compression phenomenon. We shall do this
will finish after school lol ie may idk